One of the weaknesses of the models currently available on the market is that they have been trained on a publicly accessible data set, which may not necessarily be sufficient to meet certain specific needs.
Take, for example, a company with a large volume of proprietary data, a highly specialized vocabulary or specific data formats. This knowledge will not a priori be integrated into a general-purpose model, as the data is not publicly accessible. What can be done about this? That’s what I’d like to talk about today.
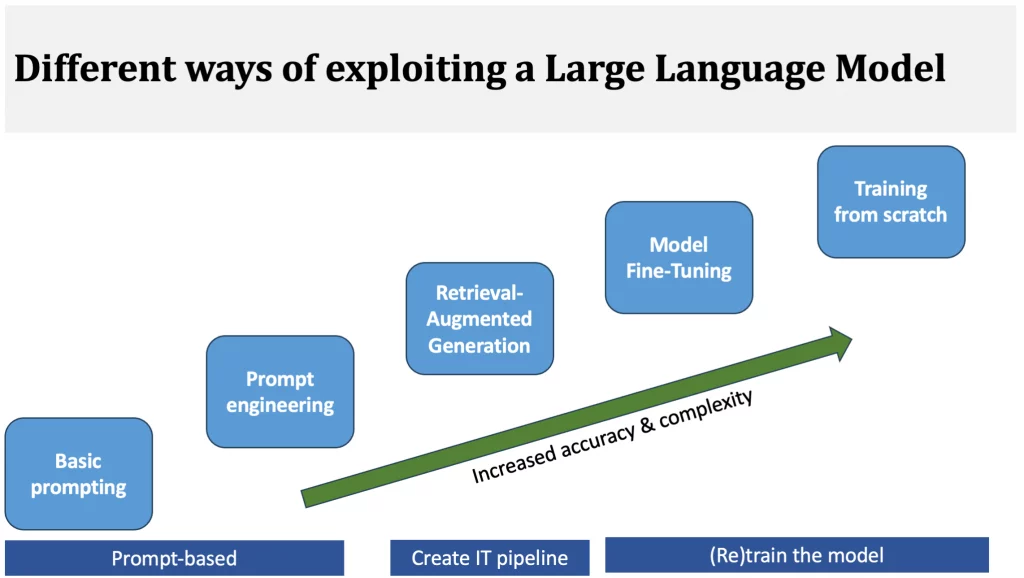
There are several techniques for “enriching” model knowledge. These include, in order of increasing complexity
- prompt engineering;
- augmented recovery generation (RAG);
- model refinement (complete or optimized).
These techniques can be found in the middle of the figure below, between the two extremes of simple dialogue and complete training:
This is an interesting topic to cover now, as it complements well our previous article on local models. Indeed, certain techniques such as refinement are mainly aimed at open-source models whose parameters are freely available.
Let’s take a look at the different techniques.
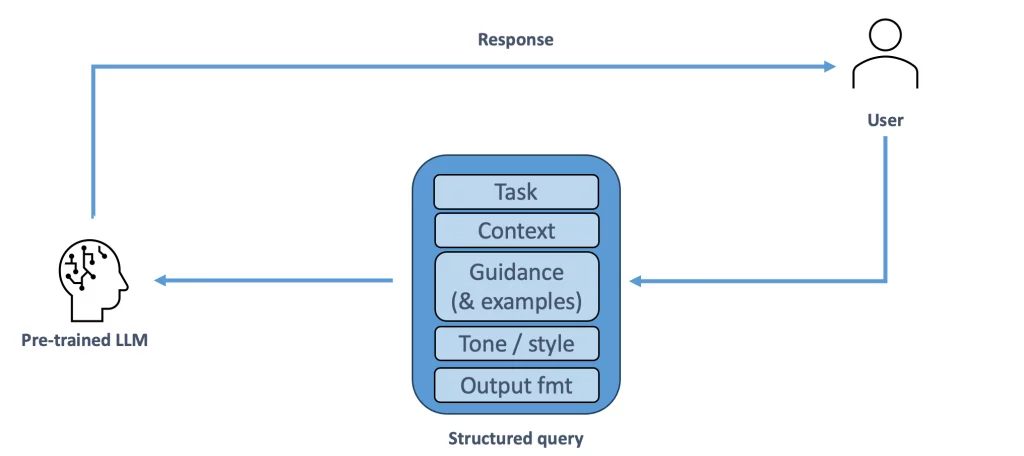
1. Prompt Engineering
Prompt engineering comprises two basic underlying techniques: the first is to provide sufficient contextual information in the prompt. The model will then combine all the information in its possession (from the training and the prompt) to answer the question posed.
The second technique involves encouraging the model to follow structured logical reasoning. Since language models have been trained to comply with the user’s instructions, they can be asked to follow a step-by-step reasoning process or to provide a series of solved examples to put the model on the right track. While not a panacea, these techniques have already proved effective.
A fun method is to promise a financial reward to the model if they answer correctly. Simply add “If you answer correctly, I’ll give you ten euros” at the end of the prompt. Believe it or not, it seems to work!
Prompt engineering can provide sufficient precision in some applications. Its main advantage is its simplicity of implementation, which also requires no additional computing resources.
But this technique comes up against the limited size of context windows in language models. It cannot be applied when the volume of information to be transmitted is too great or too complex to describe in the prompt. There is then a risk that the model will invent the missing information, resulting in incorrect or even nonsensical responses (hallucinations).
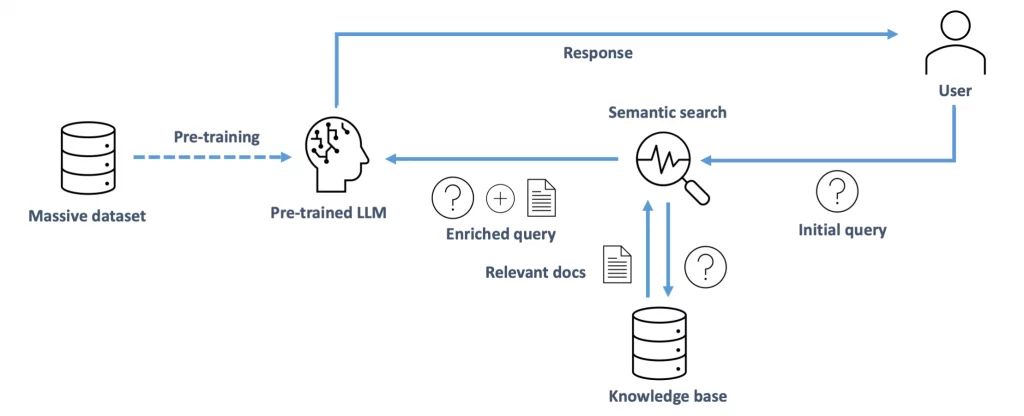
2. Retrieval Augmented Generation (RAG)
The idea may have occurred to you on reading the previous point: why not combine prompt engineering with a search engine that indexes additional data? The result would be a prompt “enriched” with the most significant additional elements, automatically and transparently for the user…
This is the promise of Retrieval Augmented Generation (RAG). Here’s how it works:
- Additional information is broken down into blocks, each of which is indexed according to its content. These indexes are usually vectors whose position in space depends on the content of the block (semantic indexing). An introduction to this subject can be found here;
- All the indexes are stored in a vector database, which also contains the references of the indexed text blocks;
- When a user asks a question, the question text is also indexed using the same algorithm. A search of the vector database will identify blocks semantically close to the prompt based on proximity between vectors;
- These semantically close blocks of information are concatenated with the original prompt as additional context;
- The prompt enriched with the additional context is sent to the language model for response.
This technique has several advantages. Imagine a typical set of proprietary information generated by a company: databases, PDF documents, excel files, news feeds, meeting minutes….. All this data can be sliced, semantically indexed, and fed into the vector database. And it’s easy enough to continue enriching the vector database regularly to ensure that the information remains up to date.
The second major advantage is that there’s no need to modify the language model as such. It all depends, of course, on the efficiency of the semantic indexing mechanism, but after 25 years of Internet search engines, these techniques are mature.
What’s more, a programming library like Langchain contains all the functionality needed to orchestrate interaction with the vector database and language model. In particular, this library supports a hundred or so file formats to feed the knowledge base.
The price to pay is greater complexity in the IT architecture. Several infrastructure elements have to be integrated and combined. And if a cloud-based vector database like Pinecone is used, the confidentiality risks that go with it must also be taken into account.
Finally, as context enrichment is a one-off, targeted process, this technique is not appropriate if you’re aiming to specialize a language model in a complex field such as medicine or finance.
In this case, it’s better to refine the model. That’s what we’re going to look at now.
3. Model Fine-Tuning
Model fine-tuning is a process during which an already pre-trained model undergoes additional training on a specific data set. This process capitalizes on the knowledge already integrated during initial training, reinforcing the model’s competence in a specific domain in return for a reasonable investment in computing resources.
This technique is important because the initial training of a model requires enormous resources, making it out of reach for most organizations.
Power requirements can be further reduced by using advanced refinement techniques such as LoRA (Low-Rank Adaptation). Introduced at the beginning of 2023, this method considerably reduces the number of parameters to be trained, at the cost of a slight degradation in quality.
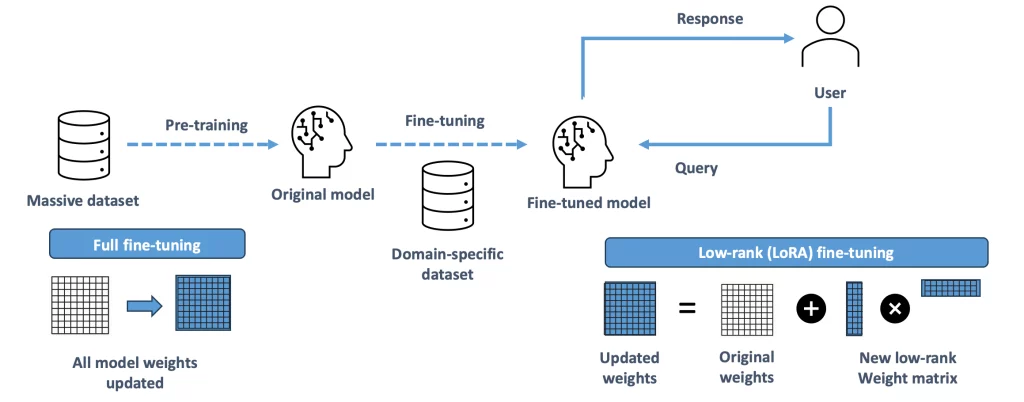
You’ll need a sufficiently large data set for further training. If you’re looking to deepen the model’s expertise in a specific domain, you can start by using any reference material on the subject you have available.
In addition, you can improve the model’s response type by adding a set of prompts and their responses to the training data. This data set may have been generated manually or via a “high-end” language model such as GPT4.
In any case, refinement remains a more complex technique, requiring sufficient AI expertise to build the dataset, implement the model training algorithm, and then evaluate the performance of the modified model. This approach also requires access to significant computing power.
One drawback of this approach compared with Augmented Recovery Generation is that it is much more difficult to introduce new information into the model: you have to go through a training phase again, with all the effort that this entails.
Another constraint of this approach is that, to modify a model, its parameters must be available. In practice, therefore, only open-source models such as Llama2 or Mistral lend themselves to this kind of exercise.
Finally, it’s worth noting that refined versions of open-source language models like Llama are available on the Internet, for specific fields such as programming. Using such a model can also be a solution…
4. Reflections
The advanced exploitation of language models described above is progressing rapidly. Optimized” refinement techniques, semantic search algorithms and vector-based RAG databases are all making steady progress.
Techniques such as RAG or refinement are too cumbersome for private use, but are an interesting solution for companies. The availability of open-source models combined with these techniques offers great deployment flexibility to organizations wishing to exploit language models to the best of their ability.
And the ability to run the whole thing “in-house” offers an elegant answer to the confidentiality concerns that hold many organizations back.
5. Notes and references
- Full Fine-Tuning, PEFT, Prompt Engineering and RAG: Which One is Right for You ?, by Najeeb Nawani for Deci.ai, Sept. 20th 2023: https://deci.ai/blog/fine-tuning-peft-prompt-engineering-and-rag-which-one-is-right-for-you/
- Qu’est-ce que la génération augmentée de récupération (RAG, retrieval-augmented generation) ?, by Alan Zichik for Oracle, Sept. 19th 2023: https://www.oracle.com/fr/artificial-intelligence/generative-ai/retrieval-augmented-generation-rag/
- LLM Explained: The LLM Training Landscape, by Crystal Liu on Medium, Aug. 7th, 2023: https://liu-gendary.medium.com/llm-explained-the-llm-training-landscape-82c803495caa
- Making LLMs Work For Your Use-Case – Fine-Tuning vs. RAG vs. Long Context Length vs. Prompting, tweet by Bindu Reddy: https://twitter.com/bindureddy/status/1712257709918318898
- The Art of Fine-Tuning Large Language Models, tweet by Bindu Reddy: https://twitter.com/bindureddy/status/1699275289493430699
- Vector Embeddings for Developers: The Basics, par Roie Schwaber-Cohen on Pinecone.io, June 30th 2023: https://www.pinecone.io/learn/vector-embeddings-for-developers/
Translated with DeepL and adapted from our partner Arnaud Stevins’ blog (February. 10th, 2024).
March 24th, 2024
Leave a Reply