Language models have remarkable qualities. Their ability to analyze complex human language queries, which comes from training on the immense volumes of textual data accessible on the Internet, was enough to provoke enthusiasm. However, these algorithms model only one component of human perception: text.
Multimodal models aim to overcome this limitation by natively processing different types of data, such as text, images, sounds and even video ( modalities).
The first multimodal models are already available on the market: OpenAI combines ChatGPT4 with GPT-4V (image recognition), DALL-E 3 (image generation), Whisper (speech recognition) and TTS (text-to-speech) to meet the most varied user requirements. Google Gemini Ultra offers comparable capabilities, and Anthropic is not to be outdone, since the new Claude 3 Opus model launched two weeks ago is also multimodal.
The new frontier is video. OpenAI recently revealed the Sora text-to-video model, which creates videos of up to 60 seconds based on a simple text prompt. Take a look at their impressive demonstration:
A word of terminology before going into detail: the acronym for multimodal models is LMM (“Large Multimodal Models”), as opposed to language models known as LLM (“Large Language Models”).
Learning by representation
The secret sauce that makes multimodal models work is representation learning. It will transform a concept presented in its “humanly intelligible” form into a vector, i.e. a sequence of numbers of fixed size.
In the case of a language model, this representation will map each word (or, more precisely, each token) to a vector. These vectors are generally high-dimensional: we’re talking about 1536 and 3072 dimensions for the two text representation models used by OpenAI described here.
This representation is designed to preserve semantic correspondence. In other words, the distance between vectors measures their semantic proximity (vectors for ‘car’ and ‘van’ will be close to each other). Even stronger, the differences between vectors correspond to other, more elementary concepts: the difference between the vectors “king” and “queen” is close to that between the vectors “man” and “woman”. The same applies to the differences between a verb’s genitive and its past tense!
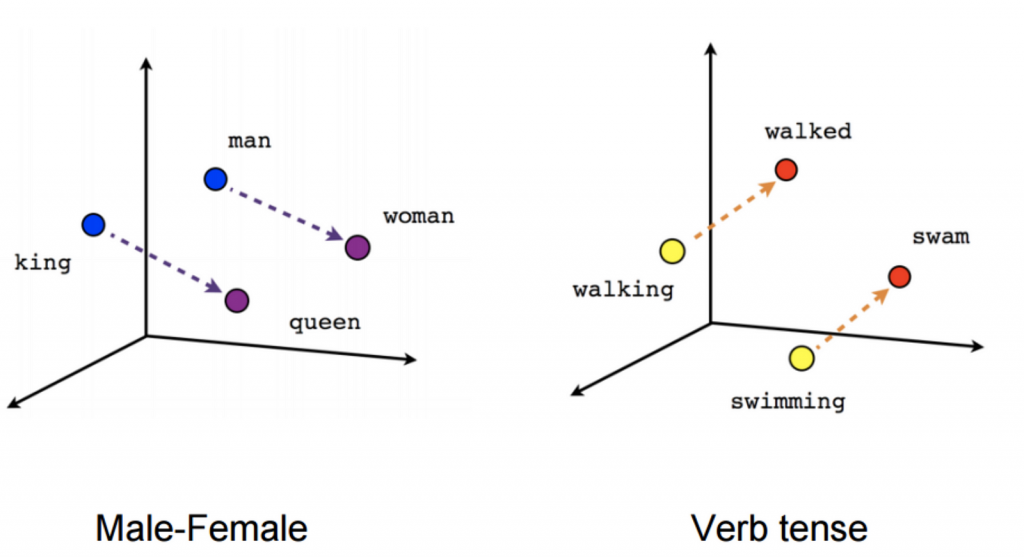
Source: https://towardsdatascience.com/word-embedding-with-word2vec-and-fasttext-a209c1d3e12c)
This notion of representation lies at the heart of all generative language models, which are nothing more or less than machines for extending sequences of vectors. At the heart of the language model lies the algorithm called transform, whose action can be summarized as follows:
- Represent the input text as a sequence of vectors;
- Transform the sequence of vectors through various mathematical operations that enrich and combine the vectors in the prompt word sequence to create new ones;
- Repeat the above action a number of times, until a final sequence of vectors is obtained;
- Use this “enriched” final sequence of vectors to predict the next vector in the sequence, and therefore the next word;
- Repeat the whole process, adding the predicted word to the end of the sequence to predict the next word etc…
In addition to generative models, the technique of textual representation makes language processing much easier: text search, grouping and classification become much less mysterious when you realize you can perform them on vectors.
What’s more, imagine having learned a representation for the entire French vocabulary. And another representation for German, but in a space of the same dimensionality… you can then define a transformation between the vector spaces that will enable you to switch from one language to the other!
Different types of representation
What applies to text also applies to images and sounds. Given a sufficient volume of training data, it is possible to define an image representation, which will also map each image to a representation in vector space.
As with text, the vector will capture the visual content of the image, which can then be used for various automated vision tasks: object detection, image classification, facial recognition, image search by similarity…
In concrete terms, this means that images containing cars will be represented by similar vectors, as will those containing dogs, buildings or any other material object. Ideally, the dimensionality of the vector will be sufficient to model complex visual situations containing several objects, taking into account their respective positioning and other features appearing in the image.
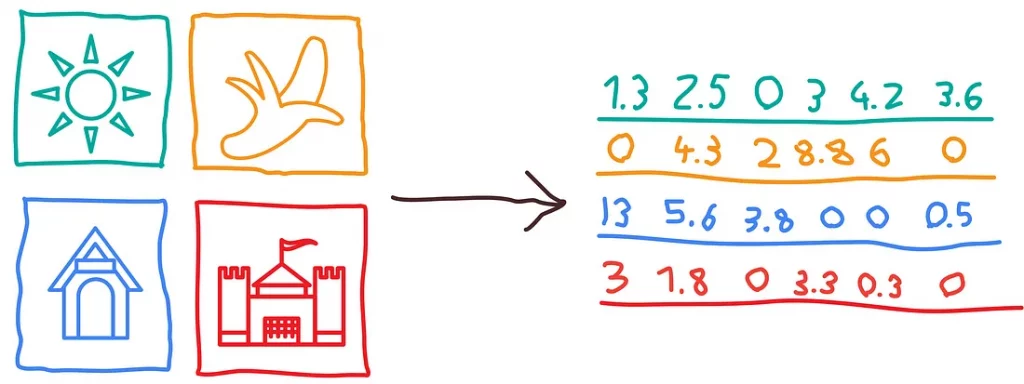
Source: https://towardsdatascience.com/image-analytics-for-everyone-image-embeddings-with-orange-7f0b91fa2ca2
And what’s possible for images is also possible for sounds. Sound representations capture the semantic and contextual content of audio files: the pronunciation of the word car and the sound of a car starting up will be linked in vector space by a proximity relationship.
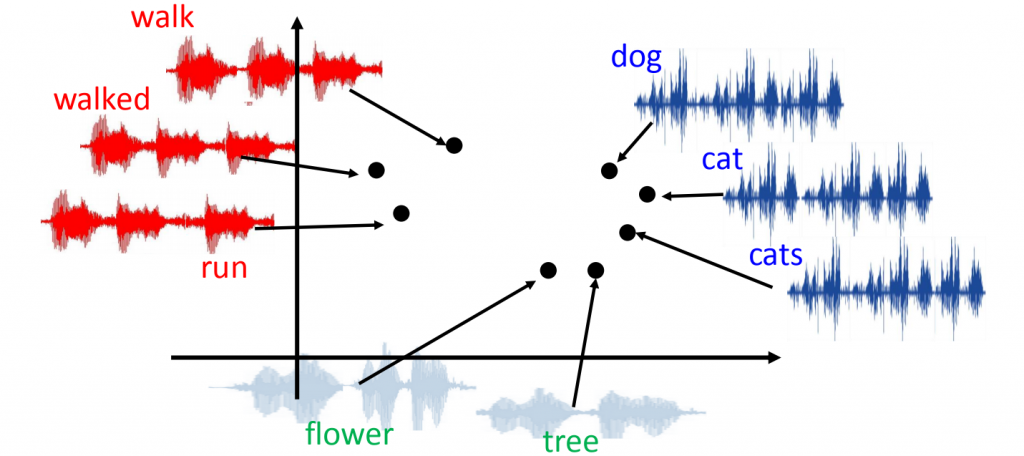
Source: https://people.csail.mit.edu/weifang/project/spml17-audio2vec/
All that’s left is to put it all together. We now have a mechanism for encoding data from different modalities in a single, multimodal representation vector space.
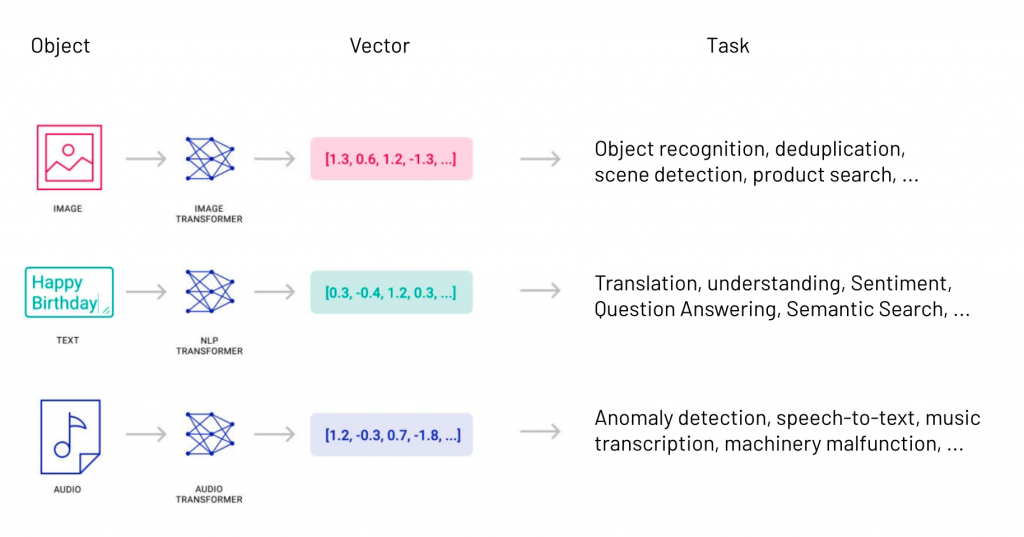
Source: https://www.pinecone.io/learn/vector-search-basics/
The final step is to integrate this into a model, usually of the transform type, which will seek to predict the next vector; you then have a multimodal model which can draw on all available sources of information to generate output data in the desired format.
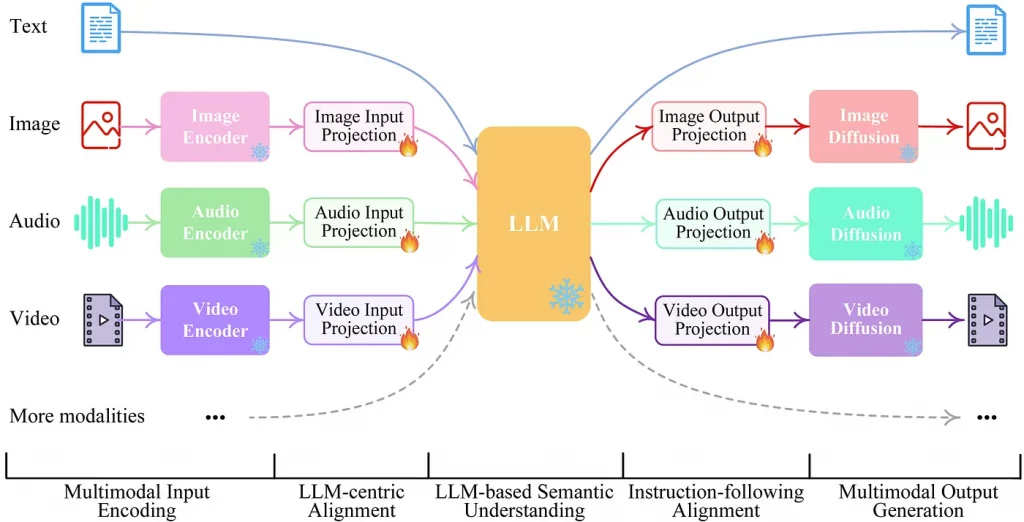
Source: https://medium.com/@cout.shubham/exploring-multimodal-large-language-models-a-step-forward-in-ai-626918c6a3ec
One small remark is that the idealized “end-to-end” multimodal model I’ve just described probably doesn’t yet exist. Current multimodal models such as those from OpenAI, Google or Anthropic are probably built as an assembly of different models, namely a unimodal language model that coordinates and calls on other “transmodal” models as required: For example, ChatGPT+ will call on DALL-E 3 if the user wants to generate an image(text-to-image), or on GPT4-V if an image is to be interpreted(image-to-text), etc. So today, we find ourselves in a multi-agent scenario.
Applications and outlook
LMMs are particularly attractive for the automation of healthcare, where patient data is dispersed across handwritten or digital text, imagery and even laboratory analysis reports in tabular form. Radiology is often cited as an example, since its raw material is imaging (CT scans, MRIs, X-rays, etc.), but there’s nothing to stop an LMM from being trained to receive and interpret other signals, such as those from an electrocardiogram.
Another field where multimodality will play an essential role is robotics, where we will be seeking to give robots the ability to perceive and interact with their environment. Consolidating this visual, auditory and textual information into a single model will enable the robot to navigate and act more effectively on the outside world.
The great challenge of multimodality, particularly for robotics, is the integration of video into the multimodal chain. The major players in the sector are working on this.
Google has an important advantage in this field, as Youtube is one of its subsidiaries. With over 500 hours of new video published every minute on Youtube, this channel constitutes an excellent reservoir of data for training future multimodal video models.
In conclusion, deep multimodal learning is an exciting and rapidly evolving field with great potential for advancing computer vision and other areas of artificial intelligence.
Although multimodal learning has its challenges, including the need for large amounts of training data and the difficulty of fusing information from multiple modalities, recent advances in deep learning models are enabling significant performance improvements across a range of tasks.
This is an area to watch out for in 2024, which could well be the year of LMMs just as 2023 was that of LLMs.
Sources and references
- Multimodal Models and Computer Vision: A Deep Dive by Petru Potrimba on Roboflow, May 10th 2023 : https://blog.roboflow.com/multimodal-models/
- Multimodal LLMs – Beyond the Limits of Language by Tim Flilzinger for Konfuzio, Oct. 19th 2023 : https://konfuzio.com/en/multimodal-llm/
- What are embeddings ?, online book by Vicki Boykis : https://vickiboykis.com/what_are_embeddings/
- Exploring Multimodal Large Language Models: A Step Forward in AI, by Shubram Karwa, Nov. 16th 2023 on Medium : https://medium.com/@cout.shubham/exploring-multimodal-large-language-models-a-step-forward-in-ai-626918c6a3ec
- The Multimodal Evolution of Vector Embeddings, by James Le, Aug. 9th 2023 on TwelveLabs : https://www.twelvelabs.io/blog/multimodal-embeddings
Translated with DeepL and adapted from our partner Arnaud Stevins’ blog (March. 18th, 2024).
March 24th, 2024
Leave a Reply