Has Sepp Hochreiter done it again? After months of announcements, a group around the inventor of the LSTM finally published a paper presenting 𝐱𝐋𝐒𝐓𝐌 to the world.
Until the appearance of the Transformer in 2017, 𝐋𝐒𝐓𝐌 had been the go-to technology for a wide variety of sequence-related tasks, including text generation. Three limitations
- the inability to revise storage decisions,
- limited storage capacity, and
- the need for sequential rather than parallel processing,
relegated LSTMs to second place behind Transformers.
The group proposes two types of new LSTM memory cells, baptized 𝐬𝐋𝐒𝐓𝐌 and 𝐦𝐋𝐒𝐓𝐌 (see the graph from the original paper below). Both sLSTM and mLSTM are placed in a residual block (adding skip connections, similar to Transformers). These blocks can be stacked in various combinations, and thus constitute the complete 𝐱𝐋𝐒𝐓𝐌 architecture.
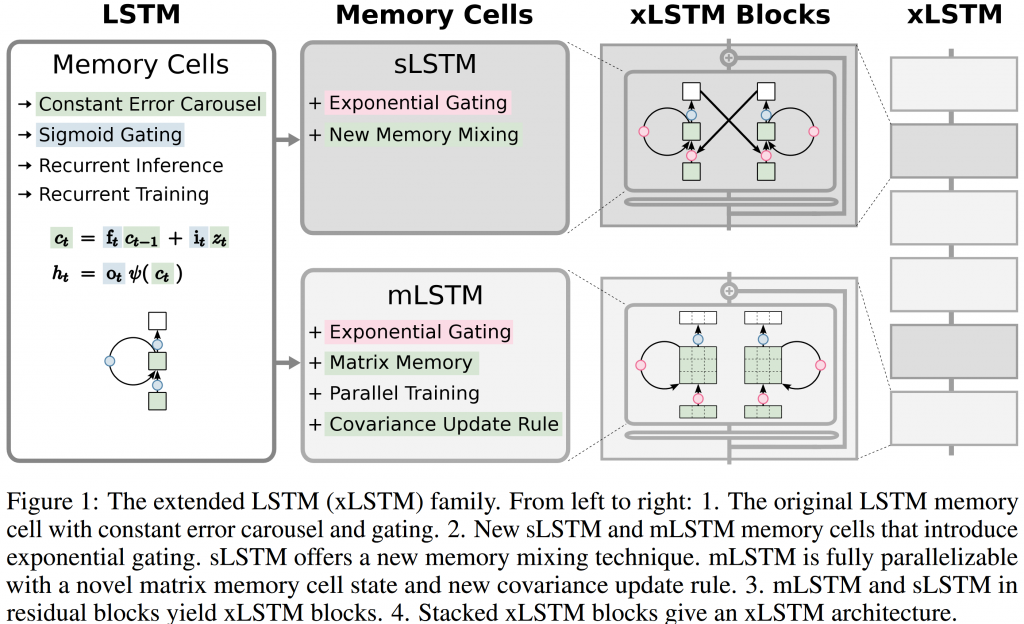
- The input and forget gates in the 𝐬𝐋𝐒𝐓𝐌 cell get exponential gates, equipping it with the ability to 𝐫𝐞𝐯𝐢𝐬𝐞 𝐬𝐭𝐨𝐫𝐚𝐠𝐞 𝐝𝐞𝐜𝐢𝐬𝐢𝐨𝐧𝐬. Identical to normal LSTMs, sLSTM can have multiple cells (one for every sequence step), allowing memory mixing. sLSTM, however, can also have multiple heads, again a Transformer idea injected into LSTMs. Memory mixing across heads is not possible.
- Instead of a scalar, the 𝐦𝐋𝐒𝐓𝐌 memory cell is a matrix for 𝐞𝐧𝐡𝐚𝐧𝐜𝐞𝐝 𝐬𝐭𝐨𝐫𝐚𝐠𝐞 𝐜𝐚𝐩𝐚𝐜𝐢𝐭𝐲. For retrieval, mLSTM adapts the key, value, and query vectors concept from Transformers. Consequently, there is no memory mixing, but multiple heads are possible here as well.
- The memory mixing in sLSTM requires 𝐬𝐞𝐪𝐮𝐞𝐧𝐭𝐢𝐚𝐥 𝐜𝐚𝐥𝐜𝐮𝐥𝐚𝐭𝐢𝐨𝐧𝐬, ruling out parallelization. Sepp Hochreiter’s team does propose a fast CUDA kernel, but the speed handicap remains.
In the experimental section, xLSTM is pitched against other methods, most notably Transformers. Overall, 𝐱𝐋𝐒𝐓𝐌 𝐜𝐨𝐦𝐩𝐚𝐫𝐞𝐬 𝐟𝐚𝐯𝐨𝐫𝐚𝐛𝐥𝐲 in many tasks, including Large Language Model. Ablation studies show that both components, sLSTM and mLSTM, contribute to the improvement over regular LSTM. An important observation is also that xLSTM scales well, so their performance is not limited to smaller datasets. Speed tests are not shown.
It will be interesting to observe to what extent xLSTM will gain traction, and what, in business speak, its key success factors will be.
Leave a Reply